
What are LLM Benchmarks?
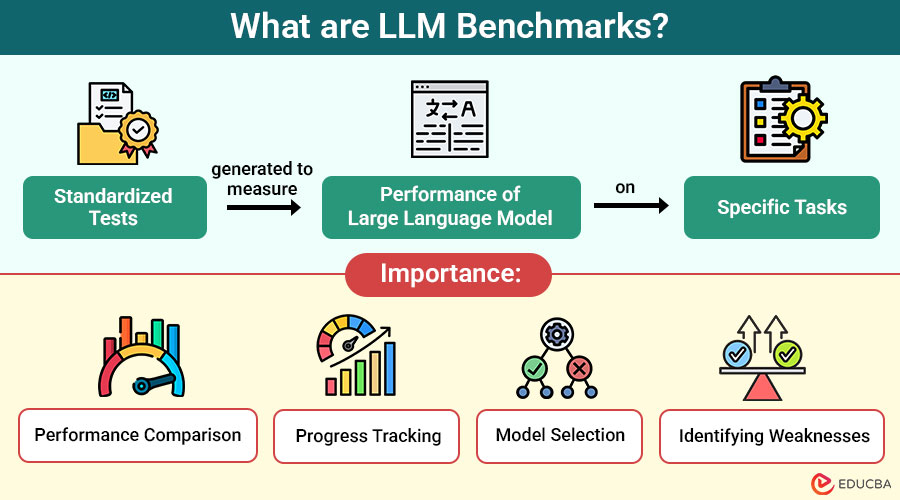
LLM (Large Language Model) benchmarks are standardized tests generated to measure the performance of large language models on specific tasks. These tasks can range from simple question-answering to complex reasoning, translation, summarization, and code generation.
Just as students take exams to demonstrate their knowledge, LLMs undergo benchmarks to validate their capabilities and compare them against those of other models.
Table of Contents:
Key Takeaways:
- LLM benchmarks evolve to match the rising capabilities of models and real-world performance expectations.
- Accurate benchmarks help identify limitations in multilingual, multimodal, and dynamic AI tasks.
- Scoring diversity ensures evaluation covers ethics, reasoning, knowledge, and user-specific challenges.
- Benchmarking drives transparency, aiding the responsible development of safe and reliable language models.
Why are LLM Benchmarks Important?
Benchmarks serve several critical functions in the development and evaluation of LLMs:
1. Performance Comparison
Benchmarks allow researchers and developers to compare different LLMs on a common set of tasks. For example, researchers can compare OpenAI’s GPT-4 with Meta’s LLaMA or Google’s Gemini on standardized tests.
2. Progress Tracking
They help track advancements over time. By observing how newer versions of models perform on the same benchmarks, we gain insight into technological improvements.
3. Model Selection
To choose the best model for their specific requirements, whether for data analysis, code creation, or customer service, businesses and developers rely on benchmark results.
4. Identifying Weaknesses
Benchmarks help identify areas where LLMs struggle, such as logical reasoning, factual accuracy, or multi-step arithmetic.
What do LLM Benchmarks Measure?
LLM benchmarks typically test a wide range of language-based capabilities:
1. Natural Language Understanding
Tests a model’s ability to comprehend language, perform sentiment analysis, answer questions, and understand reading passages accurately.
2. Reasoning
Evaluates how well a model solves logic puzzles, math problems, and applies common-sense reasoning to unfamiliar scenarios or questions.
3. Knowledge Recall
Measures the model’s ability to accurately recall historical events, scientific facts, general knowledge, and current real-world information.
4. Code Generation
Assesses the model’s skill in writing, completing, or debugging code in programming languages, based on problem descriptions or examples.
5. Translation
Examines the model’s accuracy and fluency in translating text between various languages, especially across low-resource and high-resource languages.
6. Summarization
Tests the ability to generate concise, accurate, and coherent summaries from longer texts while preserving key information and intent.
Types of LLM Benchmarks
LLM benchmarks come in various types, each designed to assess a specific aspect of a model’s capabilities:
1. Natural Language Generation
These benchmarks assess the model’s ability to generate fluent, coherent, and contextually relevant text.
Popular examples:
- BLEU (Bilingual Evaluation Understudy): Measures overlap between generated and reference translations.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Commonly used for summarization tasks.
- METEOR (Metric for Evaluation of Translation with Explicit ORdering): Evaluates both meaning and structure in generated text.
2. Knowledge and Factual Recall
This category tests whether models can recall and present accurate factual information.
Popular examples:
- OpenBookQA: Focuses on grade-school science questions that require reasoning using open-book facts.
- TriviaQA: A large-scale dataset for open-domain question answering.
- TruthfulQA: Designed to measure how likely a model is to produce false or misleading content.
3. Reasoning and Logic
These benchmarks assess the logical reasoning, problem-solving, and multi-step thinking capabilities of LLMs.
Popular examples:
- ARC (AI2 Reasoning Challenge): Tests commonsense reasoning and science questions.
- GSM8K (Grade School Math 8K): A set of math word problems suitable for testing step-by-step problem-solving.
- LogiQA: Focuses on logical reasoning derived from reading passages.
4. Coding and Math
Designed for evaluating models specialized in programming and mathematical reasoning.
Popular examples:
- HumanEval: Benchmarks code generation capabilities by asking models to generate Python functions from docstrings.
- MBPP (Mostly Basic Programming Problems): Contains Python problems with test cases to evaluate code generation accuracy.
- GSM8K (also used here for math): Evaluates mathematical reasoning for elementary and middle school problems.
5. Multitask and General Intelligence
These comprehensive benchmarks test multiple capabilities across varied domains and subjects.
Popular examples:
- MMLU (Massive Multitask Language Understanding): Covers 57 academic and professional topics, from biology to law and history.
- BIG-bench (Beyond the Imitation Game): A collaborative benchmark consisting of over 200 diverse tasks, ranging from creativity to reasoning and general knowledge.
- HELM (Holistic Evaluation of Language Models): HELM comprehensively evaluates language models across diverse tasks, measuring their accuracy, robustness, fairness, and overall performance.
How are LLMs Scored?
Evaluation of LLMs typically involves one or more of the following scoring mechanisms:
1. Accuracy
Measures the percentage of correct outputs produced by the model compared to the ground truth in a given task.
2. BLEU/ROUGE
Used for language generation tasks, comparing the model’s output to reference texts based on word or phrase overlap.
3. F1 Score
A balanced metric combining precision and recall, especially useful for classification tasks and imbalanced datasets.
4. Pass@k
Common in coding benchmarks, it checks whether a correct solution is among the top-k generated code outputs.
Challenges with Current Benchmarks
Mentioned below are key challenges that affect the reliability and effectiveness of current LLM benchmarking practices:
1. Overfitting and Training on Benchmarks
Some LLMs are trained or fine-tuned on the same data used in benchmarks. This can lead to artificially high scores and reduced generalization.
2. Static Benchmarks
Many benchmarks are fixed datasets. Once models perform well on them, they no longer pose a challenge to newer, more capable models.
3. Lack of Real-World Context
Benchmarks often lack the messiness of real-world data, such as mixed languages, ambiguous questions, or multi-modal content.
4. Bias and Fairness
Benchmarks may carry inherent cultural, gender, or linguistic biases, which can affect fairness across different users and use cases.
5. Evaluation Costs
Comprehensive benchmarking, especially human evaluation, can be expensive and time-consuming for large-scale models.
Recent Trends in LLM Benchmarking
Mentioned below are the emerging trends that reflect how LLM benchmarking is evolving to meet modern model capabilities:
1. Dynamic and Live Benchmarks
To address static data issues, some platforms now use dynamic evaluation, presenting previously unseen tasks or real-time user feedback.
2. Multimodal Benchmarks
With the rise of multimodal models, new benchmarks now include images, audio, video, and text as inputs.
3. Agentic Benchmarks
For autonomous agents built on LLMs, new benchmarks are emerging to test multi-step planning, tool use, and interactivity.
4. Open Leaderboards
Websites like Hugging Face Open LLM Leaderboard or Papers with Code allow real-time comparison of model performance across benchmarks.
Future of LLM Benchmarks
As LLMs grow more capable and complex, benchmarking must also evolve. Here is what the future may hold:
1. Ethical Evaluation
Assess language models for safety, toxicity, fairness, and ability to mitigate bias in diverse, real-world applications and responses.
2. Task Diversity
Introduces benchmarks with broader linguistic and cultural representation, including non-Western languages, idioms, and region-specific knowledge or expressions.
3. Simulated Environments
Uses interactive simulations or game-like settings to evaluate dynamic reasoning, adaptability, and decision-making in complex virtual tasks.
4. Long-Term Memory Evaluation
Tests a model’s ability to retain, recall, and apply previously learned or referenced information across multiple interactions or sessions.
Final Thoughts
LLM benchmarks are tools used to evaluate the intelligence, accuracy, and utility of large language models. They range from basic comprehension to advanced reasoning and coding tasks. While vital for AI progress, they should guide continuous improvement rather than serve as final goals. Understanding these benchmarks offers valuable insight into the evolving capabilities of modern AI systems.
Frequently Asked Questions (FAQs)
Q1. How do LLM benchmarks influence the development of new models?
Answer: LLM benchmarks guide researchers on where current models fall short, helping shape future architectures and training strategies. They provide measurable goals, encouraging innovation in areas such as reasoning, multilingual understanding, and factual accuracy.
Q2. Are there benchmarks for languages other than English?
Answer: Yes, though many benchmarks are English-centric, there is growing emphasis on multilingual evaluation. New datasets, such as XGLUE, FLORES, and XTREME, aim to test performance across diverse global languages, including those with low resources.
Q3. Can benchmarks predict how an LLM will perform in real-world tasks?
Answer: Not always. Benchmarks provide a controlled measure of capability, but real-world use involves unpredictable input, dynamic contexts, and user interaction—factors that most static benchmarks don’t fully replicate.
Q4. Do higher benchmark scores always mean a better model?
Answer: Not necessarily. A model may score well by overfitting or exploiting the quirks of the benchmark. Practical usefulness also depends on factors like latency, cost, ethical behavior, and robustness, not just scores.
Recommended Articles
We hope that this EDUCBA information on “LLM Benchmarks” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
- What is NLP?
- Types of Computer Language
- Artificial Intelligence Techniques
- Artificial Hallucinations in ChatGPT